
A Crash Course on Scaling the API Layer
A Crash Course on Scaling the API Layer

The API (Application Programming Interface) layer serves as the backbone for communication between clients and the backend services in modern internet-based applications.
It acts as the primary interface through which clients, such as web or mobile applications, access the functionality and data provided by the application. The API Layer of any application has several key responsibilities such as:
Process incoming requests from clients based on the defined API contract.
Enforce security mechanisms and protocols by authenticating and authorizing clients based on their credentials or access tokens.
Orchestrate interactions between various backend services and aggregate the responses received from them.
Handle responses by formatting and returning the result to the client.
Due to the central role APIs play in the application architecture, they become critical for the application scalability.
The scalability of the API layer is crucial due to the following reasons:
Handling Load and Traffic Spikes: As applications become popular, they encounter increased traffic and sudden spikes in user demand. A scalable API can manage the increased load efficiently.
Better User Experience: The bar for user expectation has gone up. Most users these days expect fast and responsive applications. A scalable API ensures that the application can support a high number of users without compromising performance.
Cost and Resource Optimization: Scalable APIs unlock the path to better resource utilization. Rather than provisioning the infrastructure upfront for the highest demand level, instances are added and removed based on demand, resulting in reduced operational costs.
In this article, we’ll learn the key concepts a developer must understand for API scalability. We will also look at some tried and tested strategies for scaling the API layer with basic code examples for clarity. Lastly, we will also look at some best practices that can help with scaling the API layer.
Key Concepts
Let us first look at some key concepts that should be understood before going for any API scalability strategy.
Scalability
Scalability refers to the ability of the API layer to efficiently handle increased load by adding resources, such as additional server instances or computing power.
The main concern of any scalability strategy is that it should not degrade the performance of the application. A scalable API can adapt to varying levels of traffic while keeping the system responsive and available.
While vertical scaling is also a form of scaling, most modern scalability approaches leverage horizontal scaling in which more instances of the API are deployed to distribute the load.
Latency
Latency is the time taken for an API to process a request and return a response to the client.
High latency can lead to slow response times and a poor user experience. This is the reason low latency is essential for ensuring the APIs remain responsive, especially in real-time or interactive scenarios.
Minimizing latency involves optimizing various aspects of the API, such as efficient request processing, reducing network delays, and implementing caching strategies to quickly serve frequently requested data.
Throughput
Throughput is the measure of how many requests an API can handle per second or any other unit of time.
It is a key indicator of an API's scalability and performance, with higher throughput signifying the API's ability to process more requests efficiently.
Achieving high throughput involves optimizing server resources, implementing load balancing to distribute requests evenly, and using asynchronous processing to handle concurrent requests.
API Scaling Strategies
Let’s now look at some popular and battle-tested strategies for scaling the API layer.
Stateless Architecture
Building the API Layer using a stateless architecture is the key to horizontal scalability.
In a stateless architecture, each instance of an application operates independently, without storing any session-specific data within its own memory or local storage. This means that the application does not maintain any state information between requests.
When a client sends a request to a stateless application, the request contains all the necessary information for the application to process it. The application does not rely on any stored context from previous requests. Each request is treated as an independent transaction, and the application generates a response based solely on the information provided in the request.
Some key benefits of stateless architecture are as follows:
Horizontal Scalability: Stateless applications can scale horizontally by adding more instances as the workload increases.
Fault Tolerance: In a stateless architecture, if an instance fails or becomes unavailable, it does not impact the overall functionality of the application.
Flexibility: Since instances do not maintain a persistent state, they can be added, removed, or replaced without complex state migration or coordination.
While stateless architecture offers numerous benefits, it raises the question of how to handle session data that needs to persist across multiple requests. In a stateless application, session data cannot be stored within the application instances themselves.
To address this challenge, stateless architectures often rely on external storage solutions like databases or in-memory storage solutions like Redis or Memcached to manage session data. These storage systems provide a centralized and distributed place that all instances can access.
The diagram below shows such a design on a high level.
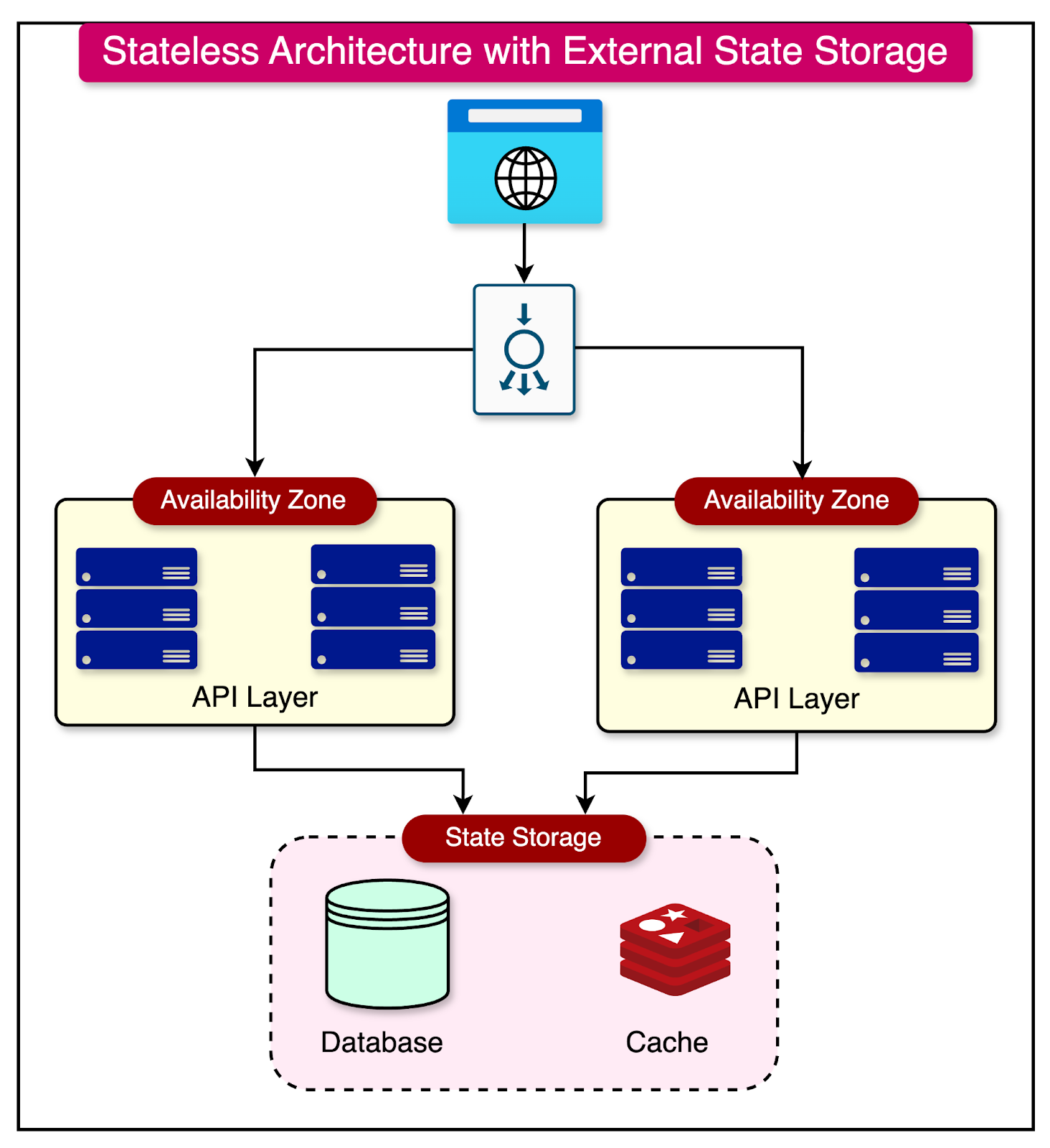
Most frameworks used to build API layers support this sort of integration out of the box.
For example, in the popular Spring Boot framework, the spring-session-data-redis dependency automatically configures the application to use Redis as the backing store for HTTP sessions.
See the sample code below for reference:
@RestController
@RequestMapping("/session")
public class SessionController {
@GetMapping("/set")
public String setSession(HttpSession session) {
// Set session attribute
session.setAttribute("user", "John Doe");
return "Session data set for user: John Doe";
}
@GetMapping("/get")
public String getSession(HttpSession session) {
// Retrieve session attribute
String user = (String) session.getAttribute("user");
return "Session data: " + (user != null ? user : "No session data found");
}
}Note that this is just an example code to demonstrate using a separate storage to store session data.
Load Balancing
Load balancing involves distributing incoming network traffic across multiple servers to ensure no single server is overwhelmed.
Some important use cases of Load Balancing are as follows:
1 - Reverse Proxy
A reverse proxy sits in front of the backend servers and handles client requests on their behalf.
When a client sends a request to the application, the reverse proxy receives the request and determines which backend server is best suited to handle it. The reverse proxy then forwards the request to the selected server and waits for the response.
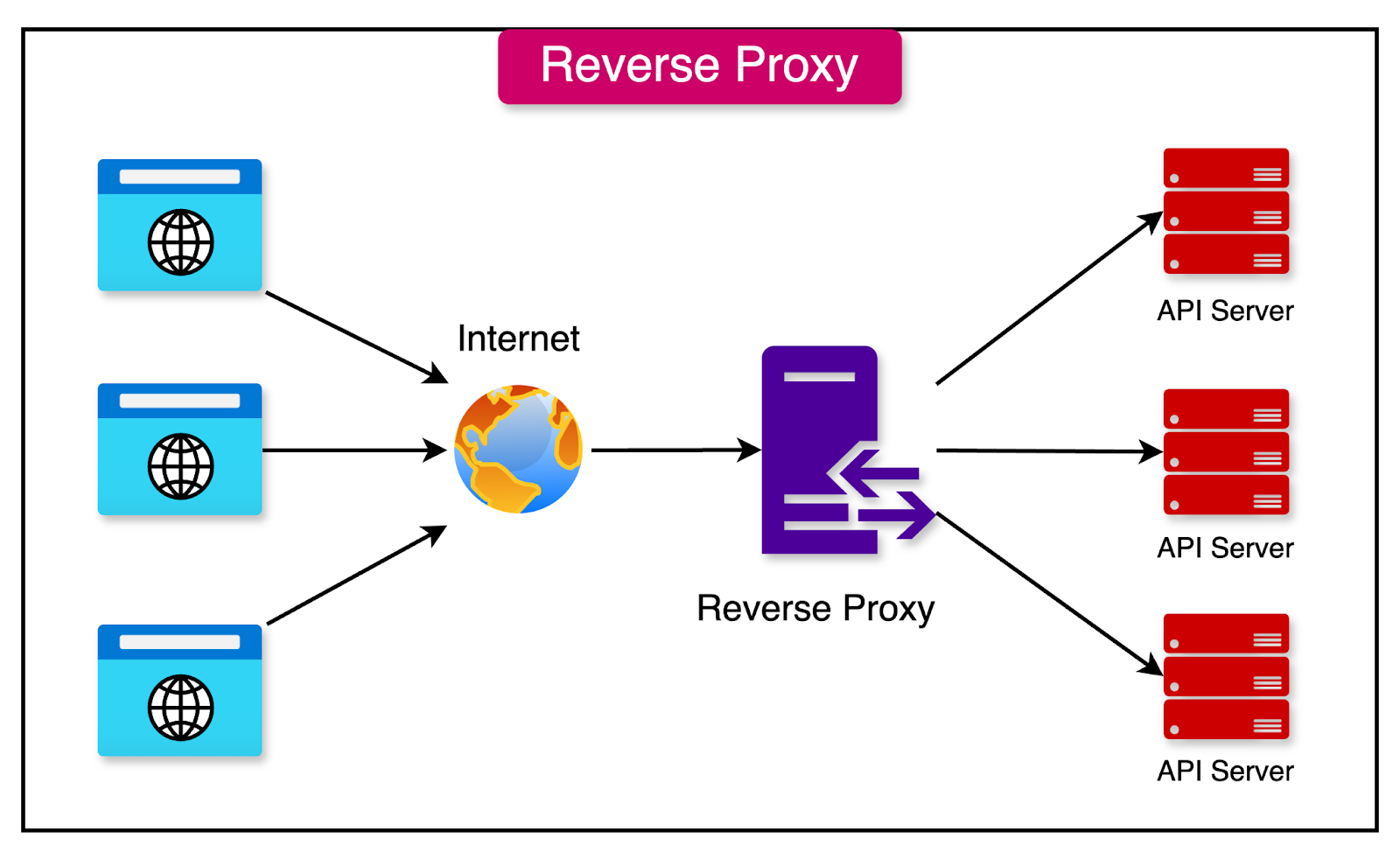
The main benefits of a reverse proxy are as follows:
Load Balancing: Reverse proxies can distribute incoming requests across multiple backend servers. Backend servers can be added, removed, or updated without affecting the client.
Increased Security: By acting as a single entry point for client requests, reverse proxies hide the internal structure of the backend servers. They can also implement additional security measures, such as SSL termination and request filtering.
Caching and Compression: Reverse proxies can cache frequently accessed content to reduce the load on backend servers and improve response times. They can also compress responses before sending them back to the client.
In modern API architectures, popular tools such as NGINX and HAProxy can be used as reverse proxies and load balancers.
Here’s a basic example of HAProxy configuration to work as a reverse proxy for load-balancing HTTP traffic across multiple backend servers. Note that this is just a demo code to explain the various options.
global
log stdout format raw local0
maxconn 4096
defaults
log global
mode http
option httplog
option dontlognull
timeout connect 5000ms
timeout client 50000ms
timeout server 50000ms
frontend http_front
bind *:80
default_backend http_back
backend http_back
balance roundrobin
server server1 192.168.1.101:80 check
server server2 192.168.1.102:80 check
server server3 192.168.1.103:80 checkHere the frontend section defines the entry point for incoming HTTP requests by listening on port 80 and forwarding the requests to the default backend http_back.
The backend section specifies the backend servers and the load-balancing algorithm.
2 - DNS Load Balancing
DNS load balancing is a technique that distributes traffic across multiple servers by leveraging the Domain Name System (DNS). It maps a single domain name to multiple IP addresses, allowing the DNS server to direct clients to different servers based on various load-balancing algorithms.
The selection of the IP address is determined by the load-balancing algorithm employed by the DNS server. Some common algorithms include:
Round Robin
Geo-location
Weighted Distribution
3 - Health Checks
Health checks are essential to ensure traffic is only directed to healthy instances.
Load balancers regularly monitor the health of backend servers by sending periodic requests to check their status.
If a server fails a health check, it is temporarily removed from the pool of available servers until it recovers. In the HAProxy example, the check option in the backend configuration enables health checks for each server.
Rate Limiting
Rate limiting is a mechanism that restricts the number of requests a client can make to an API within a predefined period.
It sets a limit on the frequency and volume of requests, preventing any single client from monopolizing the API's resources or causing performance issues for other users. This is critical for keeping the API layer scalable for the right set of users.
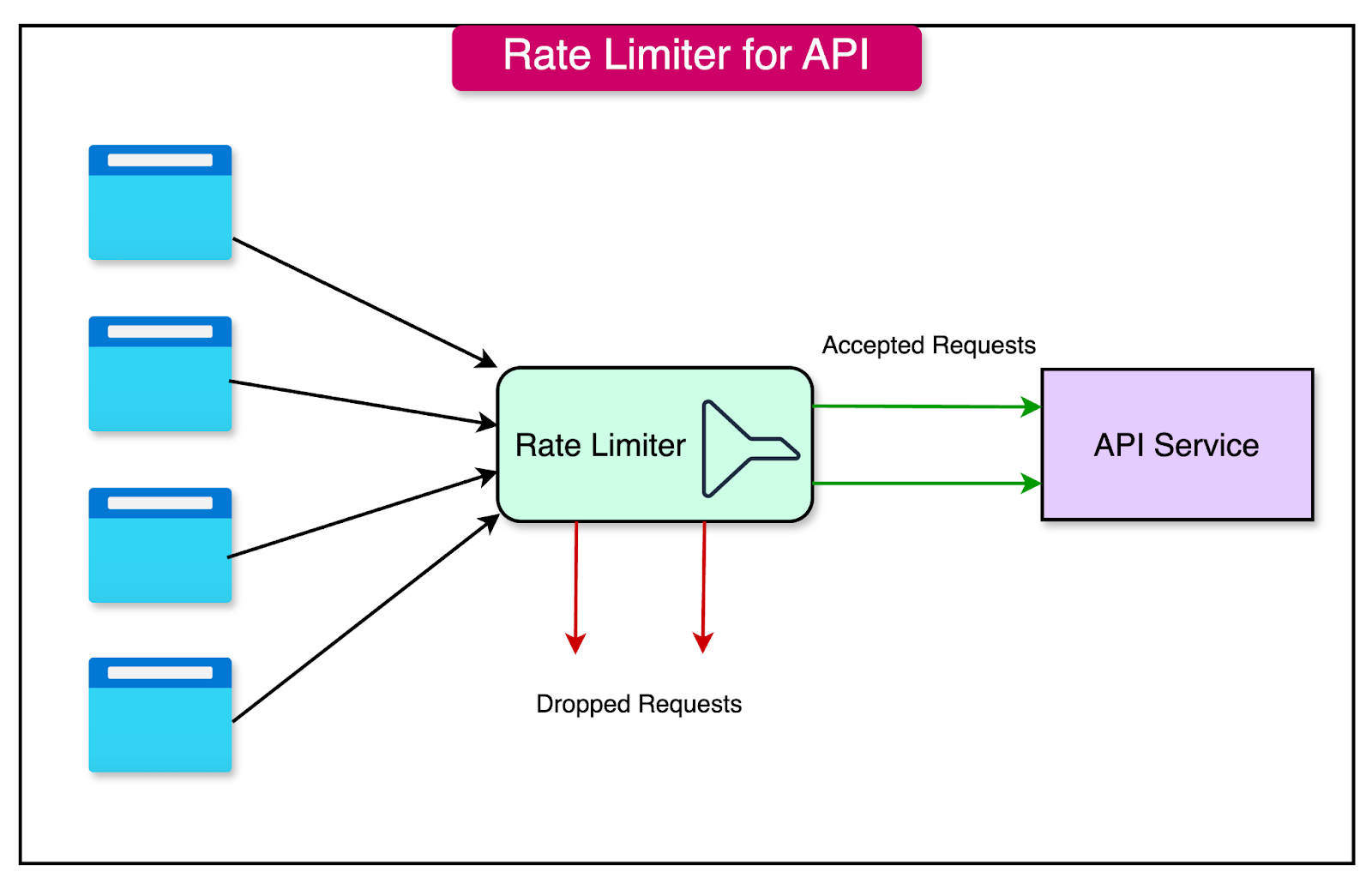
The primary goals of rate limiting are:
Preventing Abuse: Rate limiting helps mitigate the risk of denial-of-service attacks, where an attacker attempts to flood the API with a large number of requests to disrupt its functionality.
Ensuring Fair Usage: By imposing limits on the number of requests per client, rate limiting ensures that no single client can consume a disproportionate amount of resources, allowing fair access for all users.
Protecting Backend Services: Rate limiting acts as a safeguard for backend services, preventing them from being overwhelmed by excessive traffic.
When implementing rate limiting, there are several key aspects to consider:
Quota-Based Limits: Rate limiting often involves setting a quota or a maximum number of requests a client can make within a specific time frame. For example, an API may allow a particular client to make 1000 requests per hour. Once the quota is exceeded, additional requests are rejected or delayed until the next time window begins.
Granularity: Rate limits can be applied at different levels of granularity, depending on the specific requirements of the API. Common granularity levels include:
Per User: Each user is assigned a separate quota, ensuring that individual users cannot exceed their allocated limits.
Per IP Address: Rate limits are enforced based on the client's IP address, preventing a single IP from making excessive requests.
Per API Key: If the API uses API keys for authentication, rate limits can be associated with each API key, allowing for more fine-grained control over client access.
Response Headers: To provide transparency and help clients manage their request rates, APIs often include rate-limiting information in the response headers. By including these headers, APIs enable clients to monitor their usage and adjust their request patterns accordingly. These headers may include:
X-RateLimit-Limit: The maximum number of requests allowed within a time window.
X-RateLimit-Remaining: The number of remaining requests available for the current time window.
X-RateLimit-Reset: The timestamp or duration indicating when the rate limit will reset.
Asynchronous Processing
Asynchronous processing involves executing tasks in the background, separate from the main application thread.
By offloading time-consuming or resource-intensive tasks to a separate thread or process, the application can remain responsive and continue handling incoming requests without blocking.
Message queues play a crucial role in facilitating asynchronous communication between components of an application. They act as intermediaries, allowing components to send and receive messages asynchronously, without direct coupling or synchronous dependencies.
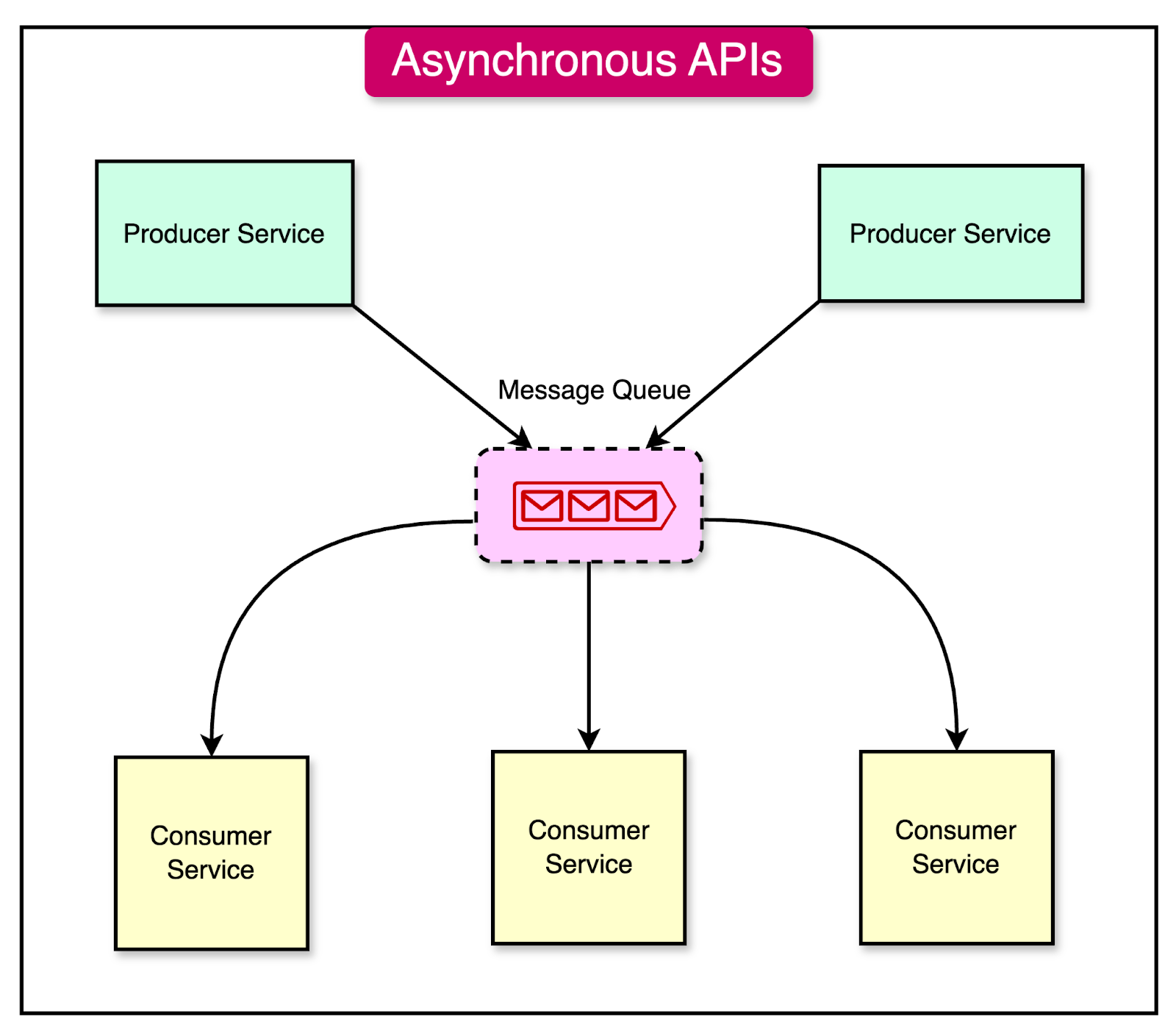
As an example, message brokers like RabbitMQ facilitate this by providing a reliable way to send, receive, and process messages. Using them, components can communicate asynchronously by sending messages to a queue and processing them independently.
Here’s a simple code sample of a MessageProducer in Spring Boot that sends a message to a RabbitMQ instance.
@RestController
public class MessageProducer {
@Autowired
private RabbitTemplate rabbitTemplate;
@GetMapping("/send")
public String sendMessage() {
rabbitTemplate.convertAndSend("myQueue", "Hello, World!");
return "Message sent!";
}
}Here’s the basic code sample of a corresponding MessageListener.
@Component
public class MessageListener {
@RabbitListener(queues = "myQueue")
public void receiveMessage(String message) {
System.out.println("Received message: " + message);
}
}In this example, a message is sent to a RabbitMQ queue, and a listener processes the message asynchronously.
Microservices Architecture
One of the most common obstacles to scaling an API is often the service supporting that API being part of a big monolithic application. It is not easy to scale such a monolithic application.
This is where using a microservices architecture can indirectly make the APIs more scalable.
Microservices architecture is an approach to designing and building applications as a collection of small, independent services that communicate with each other over a network. Each microservice represents a self-contained unit that encapsulates a specific business capability, such as user authentication, order processing, or inventory management.
See the diagram below for reference:
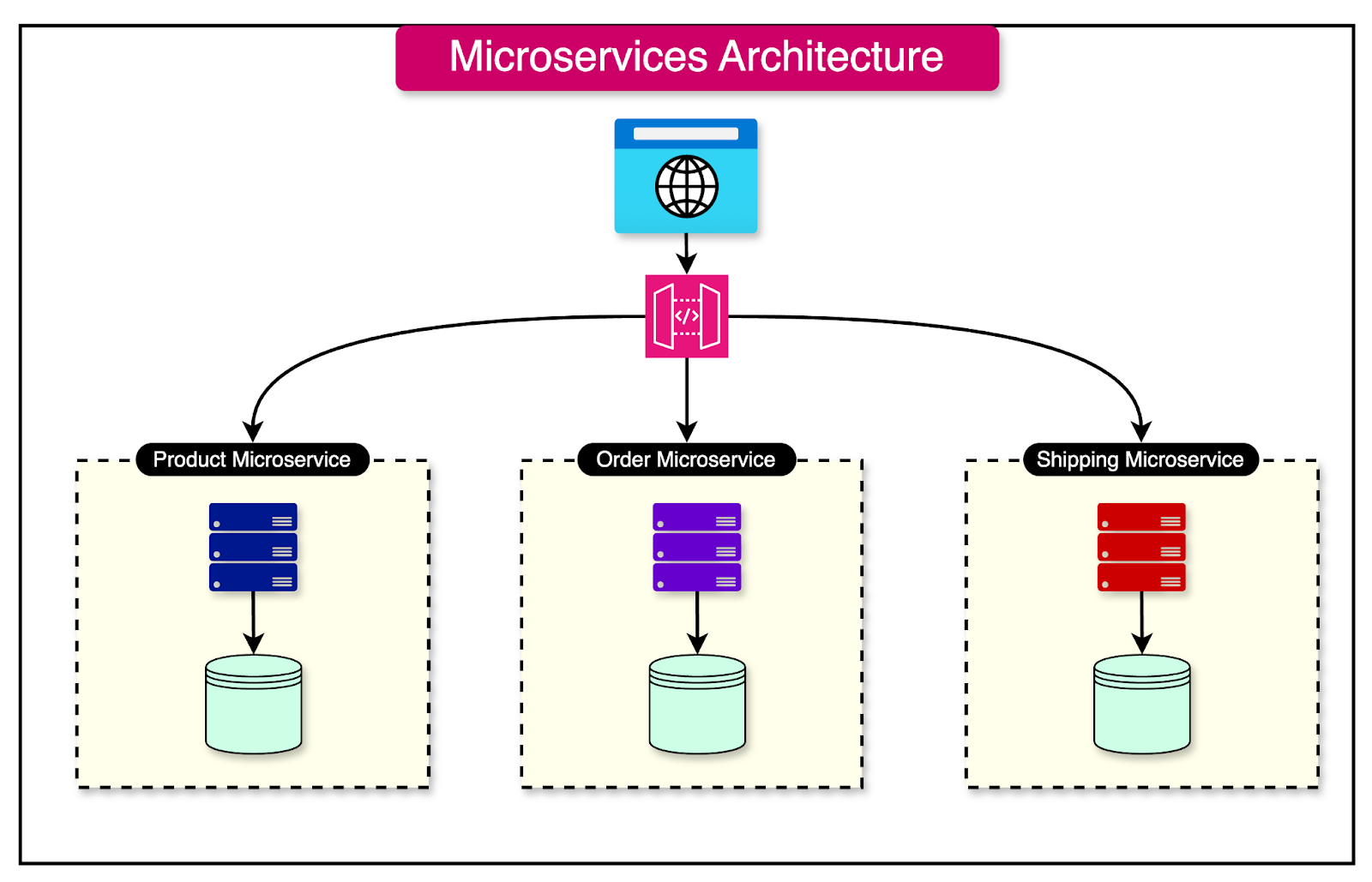
To illustrate the concept of decoupling services, let's consider an e-commerce application initially built as a monolith.
In a microservices architecture, this application could be broken down into the following services:
User Service: Manages user registration, authentication, and profile management.
Product Service: Handles product catalog, inventory, and pricing.
Order Service: Manages order creation, processing, and tracking.
Payment Service: Handles payment processing and transaction management.
Notification Service: Sends emails, SMS, or push notifications to users.
Each service can be developed, deployed, and scaled independently, allowing greater flexibility and efficiency. Also, these different services can communicate using lightweight protocols such as HTTP/REST, gRPC, or messaging systems like RabbitMQ or Kafka. The choice of communication protocol depends on the specific requirements and characteristics of the system.
By breaking down a monolithic application into smaller, loosely coupled services, the microservices architecture enables teams to develop, deploy, and scale services independently, leading to faster development cycles and more efficient resource utilization.
Best Practices While Scaling the API Layer
Implementing best practices is crucial for ensuring that the API is scalable, maintainable, and secure. Here are some practices that should ideally be followed:
Monitoring and Logging
Monitoring and logging are critical components of API management that enable developers to gain insights into the performance, health, and usage patterns of the various APIs.
Monitoring involves tracking and analyzing key metrics related to API performance and usage. Some essential metrics to monitor include:
Response Times
Error Rates
Request Volumes
To facilitate effective monitoring, various tools and platforms are available, such as Prometheus, Grafana, and the ELK Stack (Elasticsearch, Logstash, Kibana).
Logging also involves capturing detailed records of API interactions, including request and response data, timestamps, and other relevant information.
These logs are valuable for solving debugging issues, auditing usage patterns, and understanding how clients interact with the API.
API Versioning
As APIs evolve, new features may be introduced, existing functionality may be modified, or deprecated features may be removed.
API versioning enables developers to release multiple versions of the API concurrently, allowing clients to continue using the version they are familiar with while gradually transitioning to newer versions at their own pace. This approach minimizes disruption to existing integrations and ensures a smooth migration process for clients.
Common versioning strategies include:
URI Versioning
Query Parameter Versioning
Customer Header Versioning
API Security
APIs often expose sensitive data and functionality, making it crucial to implement robust security measures to protect against unauthorized access, data breaches, and other security threats.
Key components of API security include:
Authentication: Verifying the identity of users or applications accessing the API. Common authentication methods include OAuth 2.0, which enables secure delegated access, and JSON Web Tokens (JWT), which provide a compact and self-contained way to transmit authentication information.
Authorization: Determining the permissions and access rights of authenticated users or applications. Role-based access control (RBAC) and attribute-based access control (ABAC) are commonly used to enforce fine-grained authorization policies.
Data Encryption: Protecting data in transit and at rest using encryption protocols such as HTTPS/TLS for secure communication and encryption algorithms for data storage.
API Documentation
Clear, comprehensive, and up-to-date documentation is essential for reducing the learning curve, minimizing support requests, and encouraging the adoption of the API.
Effective API documentation should include:
Endpoint details
Authentication and Authorization Instructions
Error handling
Usage examples
Tools like Swagger (OpenAPI Specification) and Postman can greatly simplify the process of creating and maintaining API documentation.
Summary
APIs form the backbone of modern software development, allowing communication between the various components of distributed systems and applications.
Successfully scaling an application depends heavily on the scalability of the API layer. In this article, we’ve looked at several strategies for API scaling. Let’s go over them in brief:
The API Layer acts as the interface between clients and backend services, handling requests, enforcing security, and orchestrating service interactions.
The key concepts one should understand in the context of API scalability are the definitions of scalability, latency, and throughput.
There are multiple strategies for API scalability, especially when it comes to horizontal scalability.
Stateless architecture is the key to achieving horizontal scalability since it helps design APIs to be independent of previous requests.
Load balancing helps distribute requests across multiple instances to prevent overload. Load balancers can play the role of reverse proxy and API Gateway to provide a single entry point for the API layer.
Rate limiting is the key to controlling request volume to ensure fair usage and keep the API scalable for valid users.
Asynchronous processing helps scale the API by handling the tasks asynchronously using a background process.
Microservices architecture allows the breaking down of monolithic APIs into individual service deployments that are easier to scale.
Some best practices that support API scalability are monitoring and logging, versioning, security, and documentation.
























