

From Monolith to Microservices: Key Transition Patterns

Monolithic architecture is a software development approach in which the entire application is built as a single, unified codebase. It is often the simplest way to develop and deploy software.
For small teams or projects, monoliths provide simplicity, fast development, and easy deployment. However, as the application grows, this simplicity becomes a double-edged sword, introducing several challenges such as:
Scalability Bottlenecks: The entire application is scaled as a single unit in a monolith. If only one part of the application experiences high demand (for example, a reporting module), the entire application must scale, wasting resources on less demanding components.
Maintenance Issues: As the codebase grows, monoliths become harder to maintain. Dependencies between different parts of the application increase and each change has a larger impact radius.
Deployment Complexity: In a monolithic system, a small change in one module requires redeploying the entire application, even if the rest of the system remains unchanged.
Limited Technology Choices: All parts of a monolith must typically use the same technology stack. If the application is written in Java, for example, adding a new feature in Python or using a specialized library becomes impractical.
Resiliency Challenges: A failure in one part of a monolith can bring down the entire application.
Microservices architecture addresses the challenges of monoliths by breaking the application into smaller, independent services. Each service is responsible for a specific functionality and can be developed, deployed, and scaled independently.
However, transitioning from a monolithic architecture to microservices is a complex process. In this article, we’ll look at a few proven patterns that can help make the transition easier.
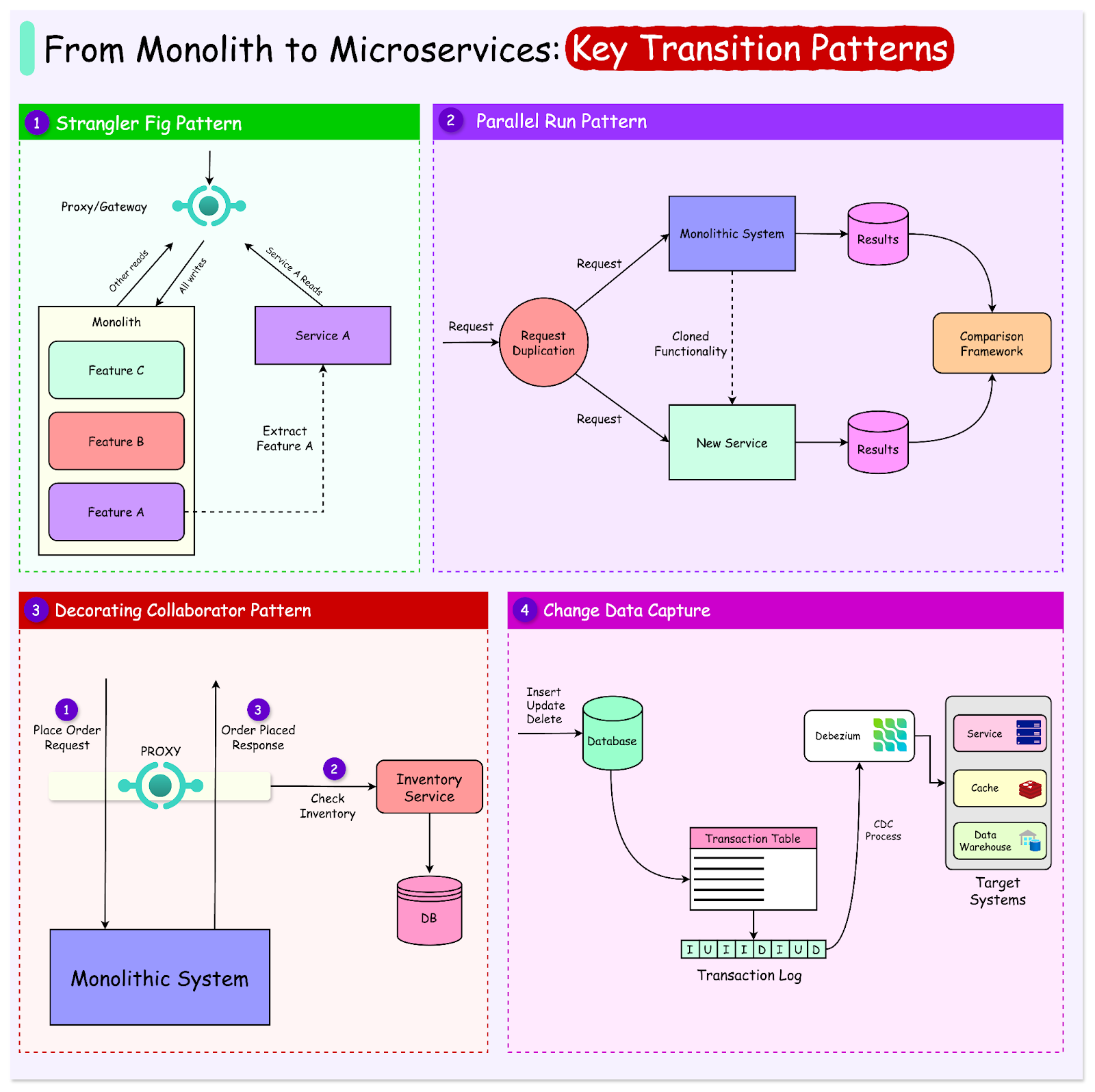
Strangler Fig Pattern
Strangler Fig is a tree that grows in a rainforest. It begins by wrapping around an existing tree, slowly replacing its structure. Over time, the fig grows stronger, and the original tree is no longer needed, leaving a self-sustaining system.
Similarly, the Strangler Fig pattern involves incrementally replacing parts of a monolithic application with microservices, leaving the old system intact until it can be safely retired.
Implementing the Strangler Fig Pattern
The diagram below shows a typical approach for applying the Strangler Fig pattern.
Here are the key steps involved:
1 - Identify Candidate Functionalities
Analyze the monolith to find self-contained, high-impact, or frequently changing functionalities (such as user management, reporting, or authentication).
We can use metrics like change frequency, dependency analysis, or error rates to prioritize components.
2 - Design the Microservice
Define the new microservice's scope, ensuring it aligns with a specific domain or functionality.
Also, a well-documented API contract must be created to communicate with other components.
3 - Implement and Test the Microservice
Implement the microservice independently, ensuring it replicates the monolith’s functionality.
Then, it must be tested thoroughly with automated tests and simulated traffic to validate correctness and performance.
4 - Set Up an API Gateway or Proxy for Routing
Introduce an API gateway or proxy like Nginx as the single entry point for client requests.
Configure the gateway to route traffic to the microservice for the extracted functionality while directing the remaining requests to the monolith.
5 - Redirect Traffic
Start by routing a small percentage of traffic to the microservice while keeping the monolith as a fallback. We can use feature toggles or canary releases to control and monitor this redirection.
In many cases, the read functionality is directed first to the service followed by the writes at a later point.
Use monitoring tools to observe traffic routed to the service and track metrics like response times, error rates, and resource utilization. Once the microservice proves stable, route all relevant traffic to it.
6 - Decommission Monolithic Components
Once a microservice handles all traffic for a specific functionality, remove the corresponding code and dependencies from the monolith.
This ensures the monolith's codebase remains manageable.
Best Practices for Strangler Fig Pattern
The Strangler Fig is one of the safest approaches to transition from a monolithic architecture to microservices.
However, some best practices to keep in mind while employing this pattern are as follows:
Begin with a low-risk, well-defined functionality to gain confidence in the transition process.
Maintain the same interface for the microservice as the monolith during the transition to avoid breaking existing clients.
Avoid big-bang rewrites. Instead, migrate one functionality at a time to minimize risk and disruption.
Implement distributed tracing and logging to monitor the interaction between the monolith and microservices.
As each microservice becomes stable, clean up the monolith by removing obsolete components to prevent "zombie code."
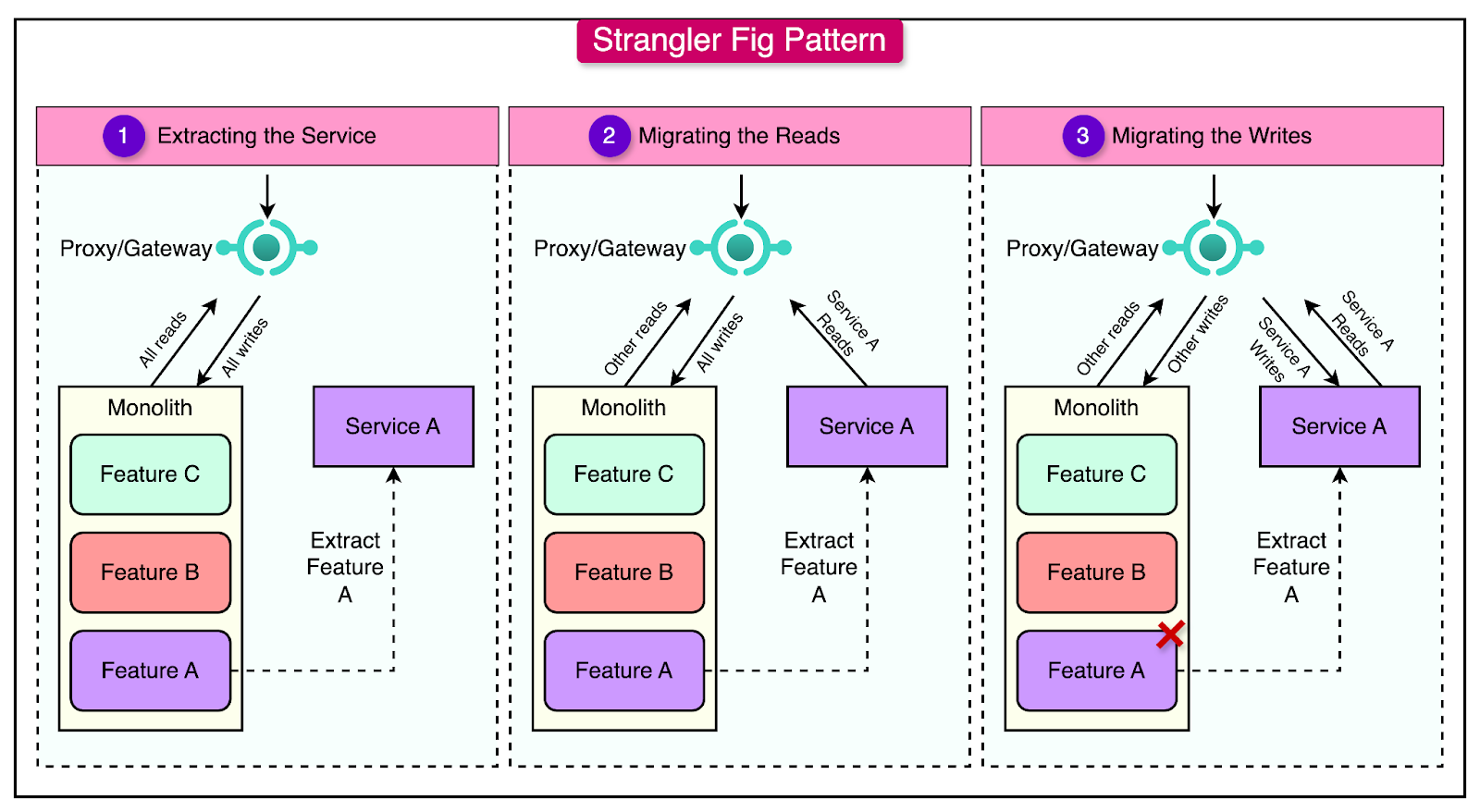
The Parallel Run Pattern
The Parallel Run pattern is a transition strategy where a monolithic application and a newly implemented microservice operate side-by-side for a specific functionality.
This allows teams to validate the new service’s performance and correctness without immediately decommissioning the monolith.
See the diagram below that shows the concept of this pattern:
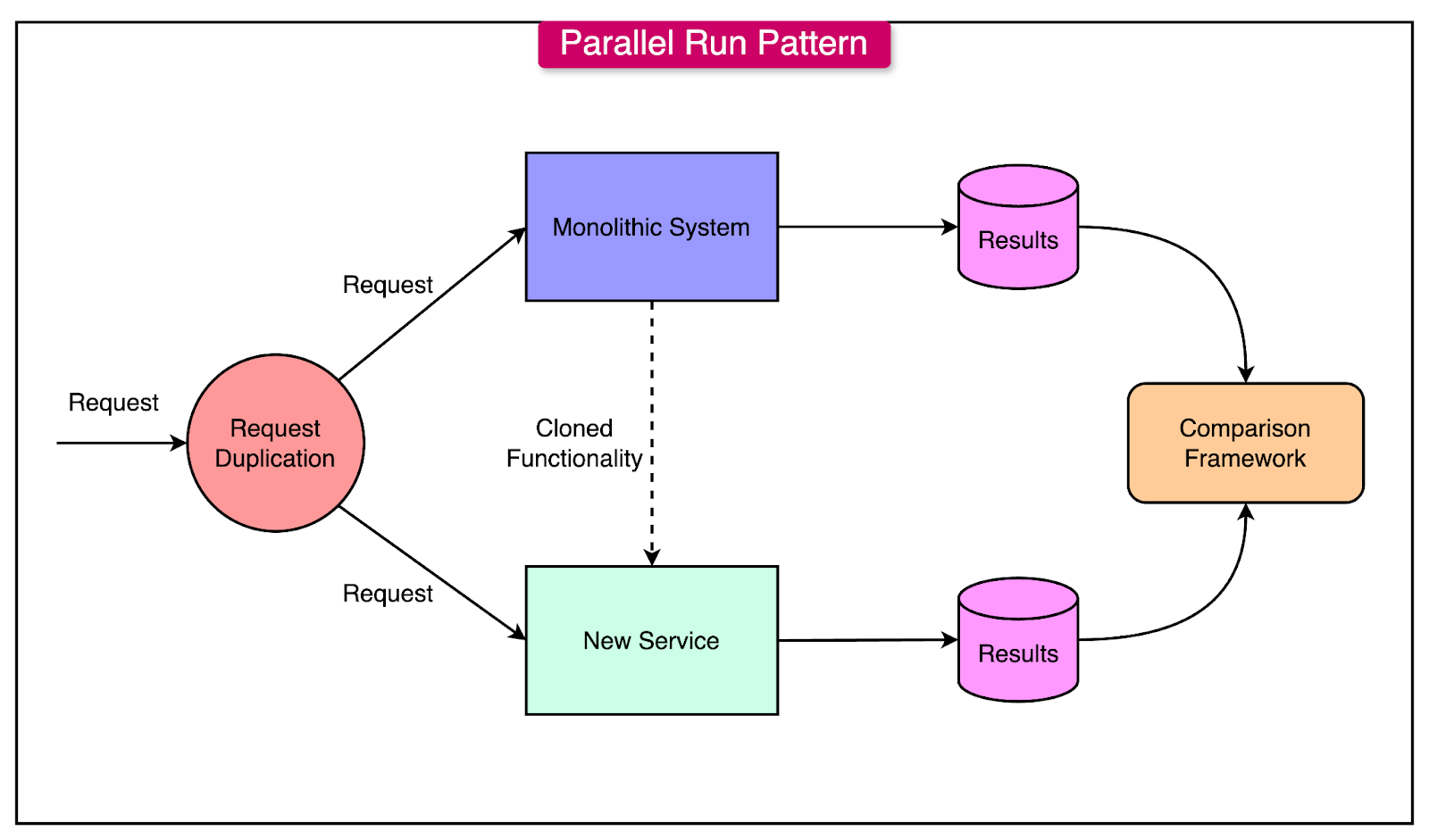
Here are the main steps involved in running the Parallel Run pattern:
Implement the functionality that needs to be transitioned from the monolith into a new microservice. Ensure both systems process the same inputs and produce identical outputs.
Duplicate incoming requests and send them to both the monolith and the microservice. The monolith continues to serve as the primary source of truth while the microservice operates in the background, providing shadow responses.
Log and compare the outputs from the monolith and the microservice. This helps identify discrepancies and ensures the microservice is functioning as expected.
Start by routing a small fraction of traffic to the microservice and monitor its behavior.
Implement fallback mechanisms so that failures in the microservice automatically redirect requests to the monolith.
Once the microservice consistently handles 100% of traffic without issues, the functionality can be removed from the monolithic system.
Some key techniques for implementing this pattern are as follows:
Traffic Splitting: Route a percentage of traffic to the microservice while the rest goes to the monolith. Tools like Envoy, Istio, or NGINX allow fine-grained control over traffic routing.
A/B Testing: Divide users into groups (for example, Group A uses the monolith, Group B uses the microservice) to test the microservice’s behavior in real-world scenarios.
Request Duplication: Duplicate requests at the gateway level and send them to both the monolith and microservice. Compare results without affecting the end-user.
Output Comparison: Use tools like Diffy to compare responses from the monolith and microservice for mismatches.
Change Data Capture
Change Data Capture (CDC) is a strategy that monitors and captures changes in a database in real-time.
In the context of transitioning from a monolithic architecture to microservices, CDC plays a crucial role in maintaining data consistency and enabling decoupling. By capturing and streaming database changes, CDC ensures that microservices remain synchronized with the monolith, even as the architecture evolves.
See the diagram below that shows the CDC process on a high level.
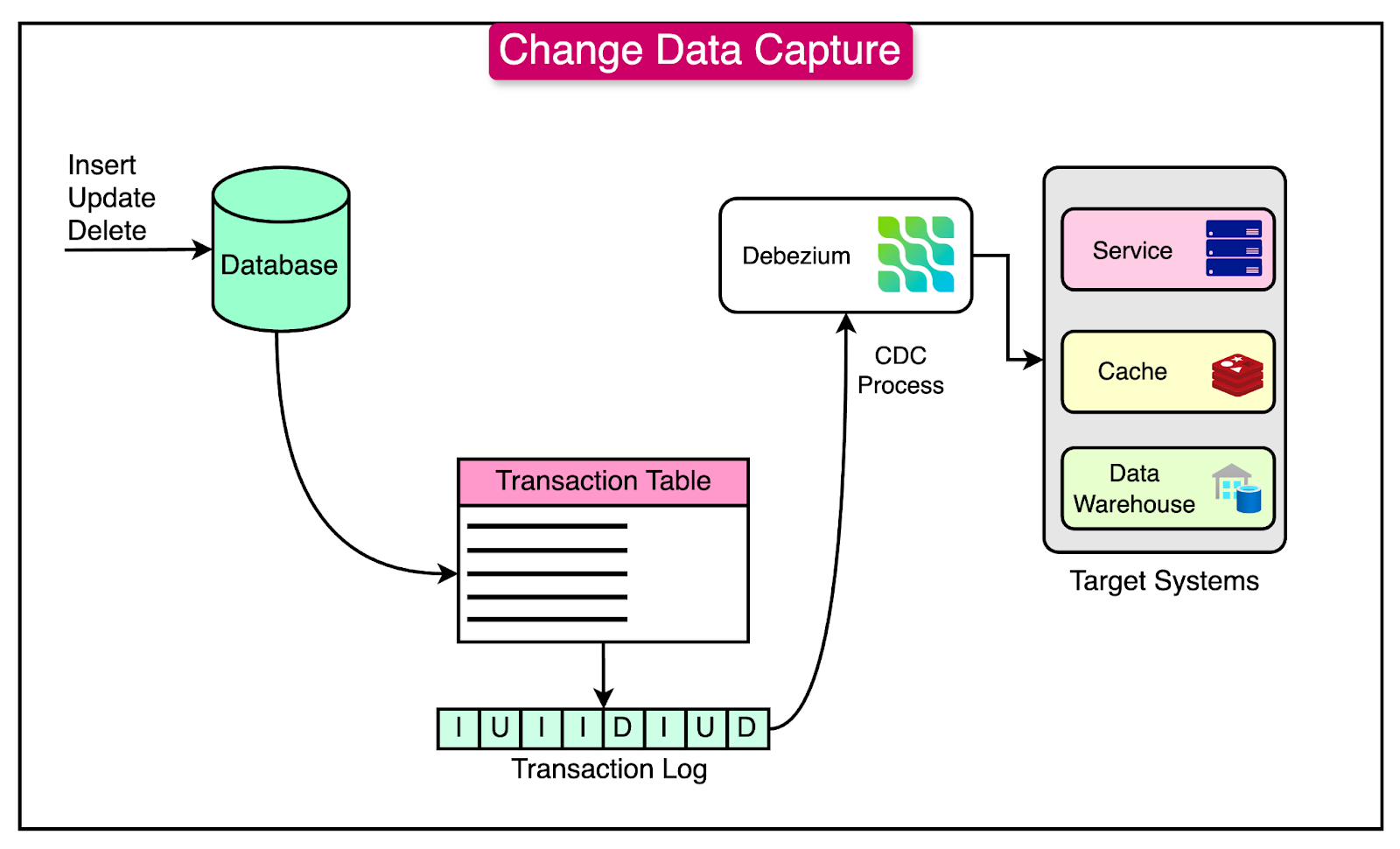
Let’s understand how the CDC pattern works in a step-by-step manner:
Capture Changes
CDC tools monitor changes (inserts, updates, deletes) in the monolith's database.
To enable CDC, the database should have a change logging mechanism in place. For example, MySQL uses binary logs to record all changes (insert, update, delete).
The database change logs become the source of truth for the CDC process, capturing every modification to the data.
Using a CDC Tool (Debezium)
Debezium acts as the bridge between the monolith’s database and the microservices architecture. It can perform the following functions:
Connects to the database and reads the change logs in real-time.
Converts these changes into standardized events (insert, update, delete).
Streams these events to a messaging platform like Kafka.
For example, If an order is created in the monolithic database, Debezium captures this as an OrderCreated event and sends it to Kafka.
Use Kafka for Event Streaming
Kafka serves as the backbone for streaming the database changes. It decouples the producer (Debezium) from the consumers (microservices), enabling asynchronous and independent processing.
The reason for choosing Kafka is because it is highly reliable, and scalable, and allows event retention for replay.
Each table or data domain corresponds to a Kafka topic. For example, An orders table in the database maps to a Kafka topic named orders. When a new order is placed, an event is published to the orders topic.
Microservice Consumes the Events
Microservices subscribe to Kafka topics to process the events they care about.
Services are responsible for processing these events and updating their data stores or triggering actions based on the event type.
For example, the Inventory service can consume OrderCreated events to update the stock levels.
Ensure Data Consistency
During the transition phase, it’s essential to validate that microservices and the monolith remain consistent:
Compare the data derived by the microservice with the monolith’s database periodically.
Use idempotent processing in microservices to handle duplicate events gracefully.
Initially, the monolithic database remains the primary source of truth.
Over time, the microservices take ownership of specific domains and the monolith delegates more responsibilities to microservices. Eventually, the monolith's dependency on its database decreases, and microservices manage their independent data stores.
The Decorating Collaborator Pattern
The Decorating Collaborator Pattern is a transition strategy where a new microservice "decorates" or augments the functionality of an existing monolithic component.
Instead of replacing the monolith’s functionality immediately, the microservice collaborates with it, enhancing or modifying its behavior. The key steps in this approach are as follows:
Identify Augmentable Features: Determine functionalities within the monolith that can benefit from augmentation or additional processing without the need to change the monolith.
Set Up Collaboration Points: Define interaction points between the monolith and the microservice. For example, these points can be before executing a specific task, after completing a task, or during execution for additional checks.
Controlled Interaction: Route specific calls through the microservice while keeping the monolith as the primary handler.
Let’s understand the process with the help of a more practical example such as augmenting a monolith's order processing system with real-time inventory checks.
Consider that initially the monolith handles order placement but does not validate inventory availability in real-time.
A new Inventory microservice is introduced to check inventory availability during the order placement process.
The monolith sends order data to the Inventory Service for validation before proceeding with processing.
The Inventory service checks stock availability and returns a response.
The monolith proceeds with order processing based on the response by the inventory service.
See the diagram below to understand the pattern:
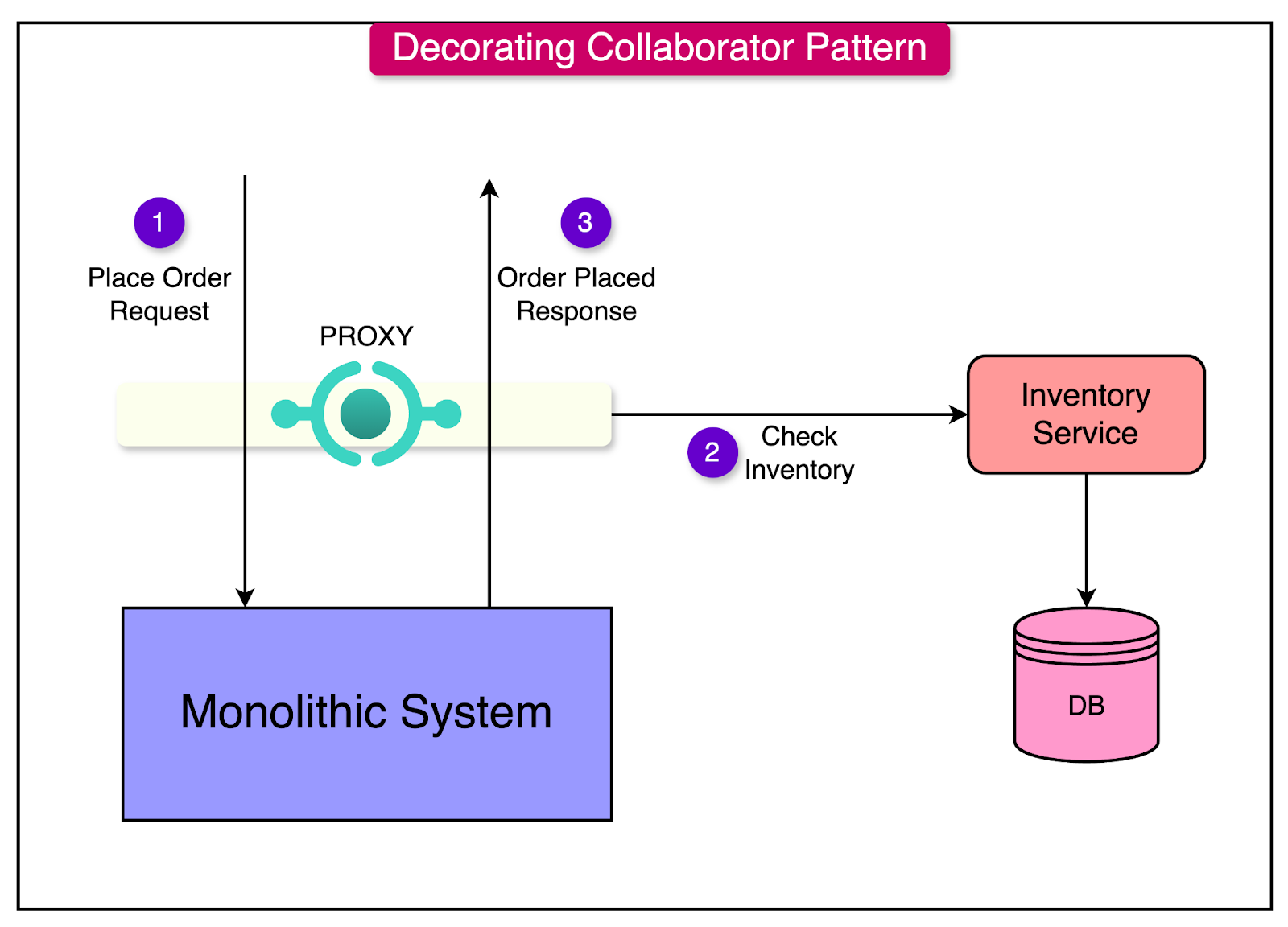
From an implementation point of view, initially, the monolith can process all orders while the Inventory service shadows and logs validation attempts.
Once confidence is built, the monolith fully relies on the Inventory service for inventory checks.
The Bulkhead Pattern
The Bulkhead pattern draws inspiration from ship design where a ship is divided into watertight compartments (bulkheads). If one compartment floods, the others remain intact, preventing the entire ship from sinking.
In software, the Bulkhead pattern involves isolating system components so that a failure in one part does not cascade to others. This is particularly important in distributed systems like microservices, where isolation ensures resilience and reliability.
The Bulkhead pattern plays a more supporting role in the transition from a monolith to microservices. It involves identifying functional boundaries within the monolith and isolating them into separate microservices. Each service operates independently, with failures contained within its scope.
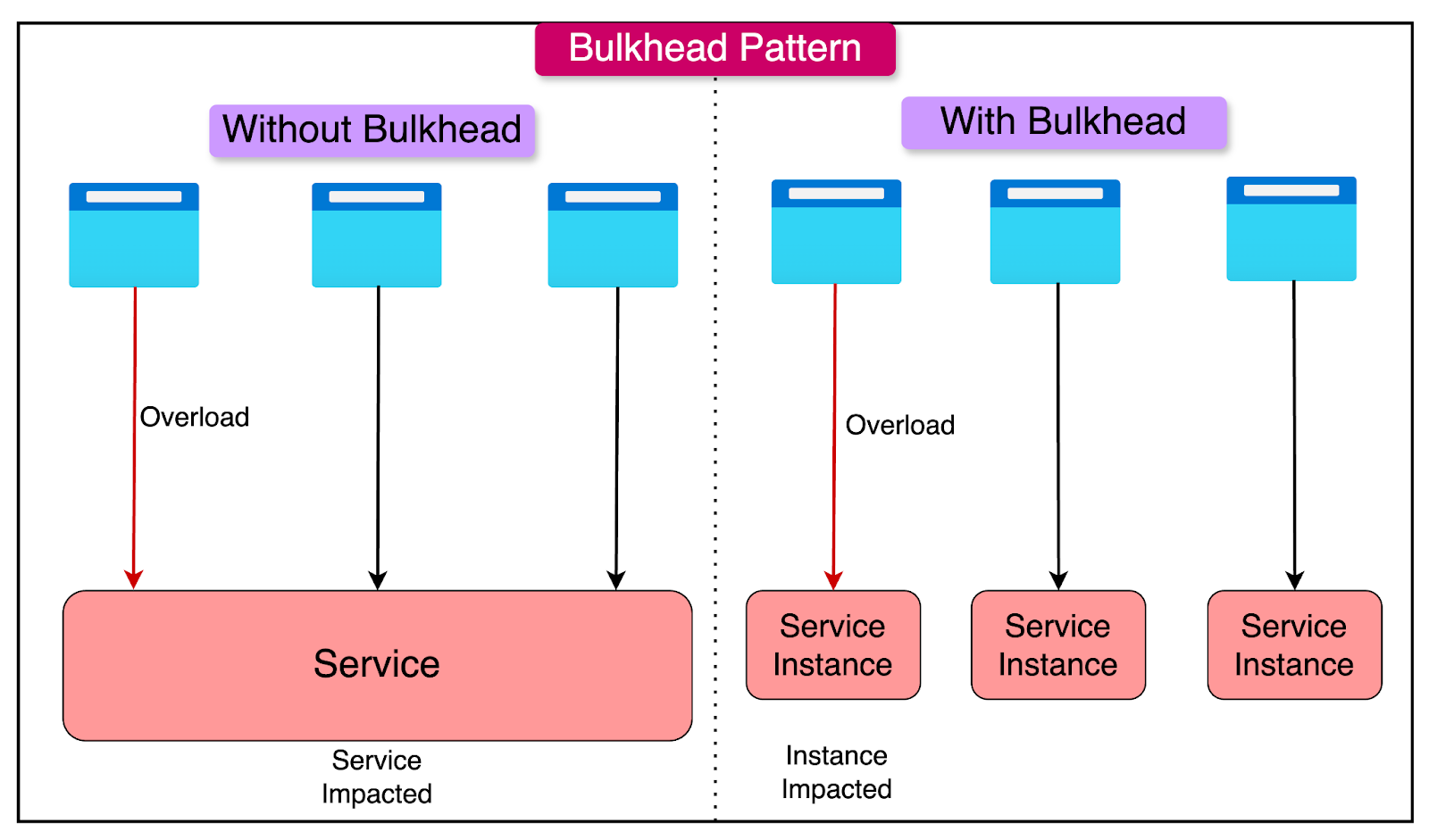
The key job is to identify boundaries in a monolith. Some steps to achieve this are as follows:
Analyze functional domains and break down the monolith into distinct business domains. Use DDD principles to identify bounded contexts that can become candidates for microservices.
Map dependencies between components. Focus on extracting tightly coupled modules that can benefit from isolation.
Target components that experience frequent changes, high traffic, or require independent scalability.
Summary
In this article, we’ve taken a detailed look at the various patterns for transitioning from a monolithic to a microservices architecture.
Let’s summarize our learnings in brief:
Monolithic architectures face challenges like scalability bottlenecks, maintainability issues, and deployment inefficiencies.
Microservices offer modularity, independent scaling, and deployment. However, transitioning from a monolithic to a microservice architecture is challenging. This is where some specific patterns can help.
The Strangler Fig pattern gradually replaces monolithic functionalities with microservices by routing traffic through an API gateway or proxy. This incremental approach minimizes risk and allows step-by-step modernization.
The Parallel Run pattern involves running the monolith and microservices side-by-side, redirecting partial traffic to validate the new services, and ensuring reliability and correctness during the transition.
The Bulkhead Pattern isolates specific functionalities from the monolith into microservices to prevent cascading failures.
CDC or Change Data Capture involves using tools like Debezium and Kafka to stream real-time database changes from the monolith to microservices to maintain data consistency during the transition.
The Decorating Collaborator pattern augments the monolith with microservices to enhance functionality without immediate replacement, allowing a gradual transition with minimal disruption.

























I would like to highlight that the opening sentence is misleading. The correct version is:
Monolithic architecture is a software design and deployment model in which all components of an application are tightly integrated and packaged as a single deployment unit, regardless of whether the underlying codebase is unified or modular.
In other words, especially for junior and middle developers, it’s not about how you write the code; it’s more about how you run it.